projects
2026
-
 APEX: Action Priors Enable Efficient Exploration for Robust Motion Tracking on Legged RobotsShivam Sood, Laukik Bhalchandra Nakhwa, Ge Sun, and 7 more authorsIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2026), 2026
APEX: Action Priors Enable Efficient Exploration for Robust Motion Tracking on Legged RobotsShivam Sood, Laukik Bhalchandra Nakhwa, Ge Sun, and 7 more authorsIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2026), 2026Learning natural, animal-like locomotion from demonstrations has become a core paradigm in legged robotics. Despite the recent advancements in motion tracking, most existing methods demand extensive tuning and rely on reference data during deployment, limiting adaptability. We present APEX (Action Priors enable Efficient Exploration), a plug-and-play extension to state-of-the-art motion tracking algorithms that eliminates any dependence on reference data during deployment, improves sample efficiency, and reduces parameter tuning effort. APEX integrates expert demonstrations directly into reinforcement learning (RL) by incorporating decaying action priors, which initially bias exploration toward expert demonstrations but gradually allow the policy to explore independently. This is combined with a multi-critic framework that balances task performance with motion style. Moreover, APEX enables a single policy to learn diverse motions and transfer reference-like styles across different terrains and velocities, while remaining robust to variations in reward design. We validate the effectiveness of our method through extensive experiments in both simulation and on a Unitree Go2 robot. By leveraging demonstrations to guide exploration during RL training, without imposing explicit bias toward them, APEX enables legged robots to learn with greater stability, efficiency, and generalization. We believe this approach paves the way for guidance-driven RL to boost natural skill acquisition in a wide array of robotic tasks, from locomotion to manipulation. We will release our full code upon paper acceptance.
-
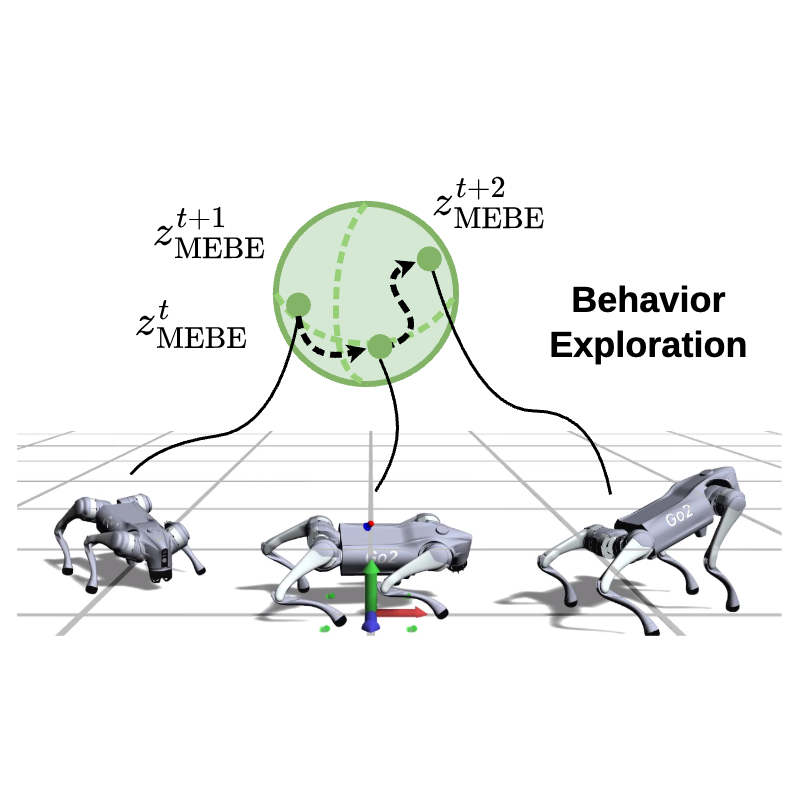 Maximum Entropy Behavior Exploration for Sim2Real Zero-Shot Reinforcement LearningJiajun Hu, Núria Armengol Urpí, Jin Cheng, and 1 more authorReinforcement Learning Conference (RLC 2026), 2026
Maximum Entropy Behavior Exploration for Sim2Real Zero-Shot Reinforcement LearningJiajun Hu, Núria Armengol Urpí, Jin Cheng, and 1 more authorReinforcement Learning Conference (RLC 2026), 2026Zero-shot reinforcement learning (RL) algorithms aim to learn a family of policies from a reward-free dataset, and recover optimal policies for any reward function directly at test time. Naturally, the quality of the pretraining dataset determines the performance of the recovered policies across tasks. However, pre-collecting a relevant, diverse dataset without prior knowledge of the downstream tasks of interest remains a challenge. In this work, we study online zero-shot RL for quadrupedal control on real robotic systems, building upon the Forward-Backward (FB) algorithm. We observe that undirected exploration yields low-diversity data, leading to poor downstream performance and rendering policies impractical for direct hardware deployment. Therefore, we introduce FB-MEBE, an online zero-shot RL algorithm that combines an unsupervised behavior exploration strategy with a regularization critic. FB-MEBE promotes exploration by maximizing the entropy of the achieved behavior distribution. Additionally, a regularization critic shapes the recovered policies toward more natural and physically plausible behaviors. We empirically demonstrate that FB-MEBE achieves and improved performance compared to other exploration strategies in a range of simulated downstream tasks, and that it renders natural policies that can be seamlessly deployed to hardware without further finetuning. Videos and code available on our website.
-
 Benchmarking Whole-Body Motion Tracking Policies via Just Dance: Using a Commercial Console Game for Embodied-AI EvaluationJeonghwan Kim, Wontaek Kim, Yidan Lu, and 10 more authorsIEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR 2026) Findings, 2026
Benchmarking Whole-Body Motion Tracking Policies via Just Dance: Using a Commercial Console Game for Embodied-AI EvaluationJeonghwan Kim, Wontaek Kim, Yidan Lu, and 10 more authorsIEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR 2026) Findings, 2026Recent advances in whole-body robot control have enabled humanoid and legged robots to perform increasingly agile and coordinated motions. However, standardized benchmarks for evaluating these capabilities in real-world settings, and in direct comparison to humans, remain scarce. Existing evaluations often rely on pre-collected human motion datasets or simulation-based experiments, which limit reproducibility, overlook hardware factors, and hinder fair human–robot comparisons. We present Switch-JustDance, a low-cost and reproducible benchmarking pipeline that leverages motion-sensing console games, Just Dance on the Nintendo Switch, to evaluate robot whole-body control. Using Just Dance on the Nintendo Switch as a representative platform, Switch-JustDance converts in-game choreography into robot-executable motions through streaming, motion reconstruction, and motion retargeting modules and enables users to evaluate controller performance through the game’s built-in scoring system. We first validate the evaluation properties of Just Dance, analyzing its reliability, validity, sensitivity, and potential sources of bias. Our results show that the platform provides consistent and interpretable performance measures, making it a suitable tool for benchmarking embodied AI. Building on this foundation, we benchmark three state-of-the-art humanoid whole-body controllers on hardware and provide insights into their relative strengths and limitations.
-
 Walk Like Dogs: Learning Steerable Imitation Controllers for Legged Robots from Unlabeled Motion DataDongho Kang, Jin Cheng, Fatemeh Zargarbashi, and 3 more authorsIn archive, 2026
Walk Like Dogs: Learning Steerable Imitation Controllers for Legged Robots from Unlabeled Motion DataDongho Kang, Jin Cheng, Fatemeh Zargarbashi, and 3 more authorsIn archive, 2026This paper presents a control framework for legged robots that leverages unstructured real-world animal motion data to generate animal-like and user-steerable behaviors. Our framework learns to follow velocity commands while reproducing the diverse gait patterns in the original dataset. To begin with, animal motion data is transformed into a robot-compatible database using constrained inverse kinematics and model predictive control, bridging the morphological and physical gap between the animal and the robot. Subsequently, a variational autoencoder-based motion synthesis module captures the diverse locomotion patterns in the motion database and generates smooth transitions between them in response to velocity commands. The resulting kinematic motions serve as references for a reinforcement learning-based feedback controller deployed on physical robots. We show that this approach enables a quadruped robot to adaptively switch gaits and accurately track user velocity commands while maintaining the stylistic coherence of the motion data. Additionally, we provide component-wise evaluations to analyze the system’s behavior in depth and demonstrate the efficacy of our method for more accurate and reliable motion imitation.
-
 Teaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and SpeechTaerim Yoon, Dongho Kang, Jin Cheng, and 5 more authorsIn submission, 2026
Teaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and SpeechTaerim Yoon, Dongho Kang, Jin Cheng, and 5 more authorsIn submission, 2026In this work, we aim to enable legged robots to learn how to interpret human social cues and produce appropriate behaviors through physical human guidance. However, learning through physical engagement can place a heavy burden on users when the process requires large amounts of human-provided data. To address this, we propose a human-in-the-loop framework that enables robots to acquire navigational behaviors in a data-efficient manner and to be controlled via multimodal natural human inputs, specifically gestural and verbal commands. We reconstruct interaction scenes using a physics-based simulation and aggregate data to mitigate distributional shifts arising from limited demonstration data. Our progressive goal cueing strategy adaptively feeds appropriate commands and navigation goals during training, leading to more accurate navigation and stronger alignment between human input and robot behavior. We evaluate our framework across six real-world agile navigation scenarios, including jumping over or avoiding obstacles. Our experimental results show that our proposed method succeeds in almost all trials across these scenarios, achieving a 97.15% task success rate with less than 1 hour of demonstration data in total.
-
 CAIMAN: Causal Action Influence Detection for Sample Efficient Loco-ManipulationYuanchen Yuan, Jin Cheng, Núria Armengol Urpí, and 1 more authorIEEE International Conference on Robotics and Automation (ICRA 2026), 2026
CAIMAN: Causal Action Influence Detection for Sample Efficient Loco-ManipulationYuanchen Yuan, Jin Cheng, Núria Armengol Urpí, and 1 more authorIEEE International Conference on Robotics and Automation (ICRA 2026), 2026Enabling legged robots to perform non-prehensile loco-manipulation with large and heavy objects is crucial for enhancing their versatility. However, this is a challenging task, often requiring sophisticated planning strategies or extensive task-specific reward shaping, especially in unstructured scenarios with obstacles. In this work, we present CAIMAN, a novel framework for learning loco-manipulation that relies solely on sparse task rewards. We leverage causal action influence to detect states where the robot is in control over other entities in the environment, and use this measure as an intrinsically motivated objective to enable sample-efficient learning. We employ a hierarchical control strategy, combining a low-level locomotion policy with a high-level policy that prioritizes task-relevant velocity commands. Through simulated and real-world experiments, including object manipulation with obstacles, we demonstrate the framework’s superior sample efficiency, adaptability to diverse environments, and successful transfer to hardware without fine-tuning. The proposed approach paves the way for scalable, robust, and autonomous loco-manipulation in real-world applications.
2025
-
 TARC: Time-Adaptive Robotic ControlArnav Sukhija, Lenart Treven, Jin Cheng, and 3 more authorsWorkshop on Aligning Reinforcement Learning Experimentalists and Theorists at NeurIPS 2025, 2025
TARC: Time-Adaptive Robotic ControlArnav Sukhija, Lenart Treven, Jin Cheng, and 3 more authorsWorkshop on Aligning Reinforcement Learning Experimentalists and Theorists at NeurIPS 2025, 2025Fixed-frequency control in robotics imposes a trade-off between the efficiency of low-frequency control and the robustness of high-frequency control, a limitation not seen in adaptable biological systems. We address this with a reinforcement learning approach in which policies jointly select control actions and their application durations, enabling robots toautonomously modulate their control frequency in response to situational demands. We validate our method with zero-shot sim-to-real experiments on two distinct hardware platforms: a high-speed RC car and a quadrupedal robot. Our method matches or outperforms fixed-frequency baselines in terms of rewards while significantly reducing the control frequency and exhibiting adaptive frequency control under real-world conditions.
-
 Whole-Body Inverse Dynamics MPC for Legged Loco-ManipulationLukas Molnar, Jin Cheng, Gabriele Fadini, and 3 more authorsIEEE Robotics and Automation Letters (RA-L) (SI: Advancements in MPC and Learning Algorithms for Legged Robots), 2025
Whole-Body Inverse Dynamics MPC for Legged Loco-ManipulationLukas Molnar, Jin Cheng, Gabriele Fadini, and 3 more authorsIEEE Robotics and Automation Letters (RA-L) (SI: Advancements in MPC and Learning Algorithms for Legged Robots), 2025Loco-manipulation demands coordinated whole-body motion to manipulate objects effectively while maintaining locomotion stability, presenting significant challenges for both planning and control. In this work, we propose a whole-body model predictive control (MPC) framework that directly optimizes joint torques through full-order inverse dynamics, enabling unified motion and force planning and execution within a single predictive layer. This approach allows emergent, physically consistent whole-body behaviors that account for the system’s dynamics and physical constraints. We implement our MPC formulation using open software frameworks (Pinocchio and CasADi), along with the state-of-the-art interior-point solver Fatrop. In real-world experiments on a Unitree B2 quadruped equipped with a Unitree Z1 manipulator arm, our MPC formulation achieves real-time performance at 80 Hz. We demonstrate loco-manipulation tasks that demand fine control over the end-effector’s position and force to perform real-world interactions like pulling heavy loads, pushing boxes, and wiping whiteboards.
-
 RAMBO: RL-augmented Model-based Whole-body Control for Loco-manipulationJin Cheng, Dongho Kang, Gabriele Fadini, and 2 more authorsIEEE Robotics and Automation Letters (RA-L), 2025
RAMBO: RL-augmented Model-based Whole-body Control for Loco-manipulationJin Cheng, Dongho Kang, Gabriele Fadini, and 2 more authorsIEEE Robotics and Automation Letters (RA-L), 2025Loco-manipulation, physical interaction of various objects that is concurrently coordinated with locomotion, remains a major challenge for legged robots due to the need for both precise end-effector control and robustness to unmodeled dynamics. While model-based controllers provide precise planning via online optimization, they are limited by model inaccuracies. In contrast, learning-based methods offer robustness, but they struggle with precise modulation of interaction forces. We introduce RAMBO, a hybrid framework that integrates model-based whole-body control within a feedback policy trained with reinforcement learning. The model-based module generates feedforward torques by solving a quadratic program, while the policy provides feedback corrective terms to enhance robustness. We validate our framework on a quadruped robot across a diverse set of real-world loco-manipulation tasks, such as pushing a shopping cart, balancing a plate, and holding soft objects, in both quadrupedal and bipedal walking. Our experiments demonstrate that RAMBO enables precise manipulation capabilities while achieving robust and dynamic locomotion.
-
 Spatio-Temporal Motion Retargeting for Quadruped RobotsTaerim Yoon, Dongho Kang, Seungmin Kim, and 4 more authorsIEEE Transactions on Robotics (T-RO), 2025
Spatio-Temporal Motion Retargeting for Quadruped RobotsTaerim Yoon, Dongho Kang, Seungmin Kim, and 4 more authorsIEEE Transactions on Robotics (T-RO), 2025This work introduces a motion retargeting approach for legged robots, which aims to create motion controllers that imitate the fine behavior of animals. Our approach, namely spatio-temporal motion retargeting (STMR), guides imitation learning procedures by transferring motion from source to target, effectively bridging the morphological disparities by ensuring the feasibility of imitation on the target system. Our STMR method comprises two components: spatial motion retargeting (SMR) and temporal motion retargeting (TMR). On the one hand, SMR tackles motion retargeting at the kinematic level by generating kinematically feasible whole-body motions from keypoint trajectories. On the other hand, TMR aims to retarget motion at the dynamic level by optimizing motion in the temporal domain. We showcase the effectiveness of our method in facilitating Imitation Learning (IL) for complex animal movements through a series of simulation and hardware experiments. In these experiments, our STMR method successfully tailored complex animal motions from various media, including video captured by a hand-held camera, to fit the morphology and physical properties of the target robots. This enabled RL policy training for precise motion tracking, while baseline methods struggled with highly dynamic motion involving flying phases. Moreover, we validated that the control policy can successfully imitate six different motions in two quadruped robots with different dimensions and physical properties in real-world settings.
-
 SATA: Safe and Adaptive Torque-Based Locomotion Policies Inspired by Animal LearningPeizhuo Li, Hongyi Li, Ge Sun, and 7 more authorsRobotics: Science and Systems (RSS 2025), 2025
SATA: Safe and Adaptive Torque-Based Locomotion Policies Inspired by Animal LearningPeizhuo Li, Hongyi Li, Ge Sun, and 7 more authorsRobotics: Science and Systems (RSS 2025), 2025Despite recent advances in learning-based controllers for legged robots, deployments in human-centric environments remain limited by safety concerns. Most of these approaches use position-based control, where policies output target joint angles that must be processed by a low-level controller (e.g., PD or impedance controllers) to compute joint torques. Although impressive results have been achieved in controlled real-world scenarios, these methods often struggle with compliance and adaptability when encountering environments or disturbances unseen during training, potentially resulting in extreme or unsafe behaviors. Inspired by how animals achieve smooth and adaptive movements by controlling muscle extension and contraction, torque-based policies offer a promising alternative by enabling precise and direct control of the actuators in torque space. In principle, this approach facilitates more effective interactions with the environment, resulting in safer and more adaptable behaviors. However, challenges such as a highly nonlinear state space and inefficient exploration during training have hindered their broader adoption. To address these limitations, we propose SATA, a bio-inspired framework that mimics key biomechanical principles and adaptive learning mechanisms observed in animal locomotion. Our approach effectively addresses the inherent challenges of learning torque-based policies by significantly improving early-stage exploration, leading to high-performance final policies. Remarkably, our method achieves zero-shot sim-to-real transfer. Our experimental results indicate that SATA demonstrates remarkable compliance and safety, even in challenging environments such as soft/slippery terrain or narrow passages, and under significant external disturbances, highlighting its potential for practical deployments in human-centric and safety-critical scenarios.
-
 Learning More With Less: Sample Efficient Dynamics Learning and Model-Based RL for Loco-ManipulationBenjamin Hoffman, Jin Cheng, Chenhao Li, and 1 more authorWorkshop on Resource-Rational Robot Learning at CoRL 2025, Workshop on Robotics World Modeling at CoRL 2025, 2025
Learning More With Less: Sample Efficient Dynamics Learning and Model-Based RL for Loco-ManipulationBenjamin Hoffman, Jin Cheng, Chenhao Li, and 1 more authorWorkshop on Resource-Rational Robot Learning at CoRL 2025, Workshop on Robotics World Modeling at CoRL 2025, 2025Combining the agility of legged locomotion with the capabilities of manipulation, loco-manipulation platforms have the potential to perform complex tasks in real-world applications. To this end, state-of-the-art quadrupeds with attached manipulators, such as the Boston Dynamics Spot, have emerged to provide a capable and robust platform. However, both the complexity of loco-manipulation control, as well as the black-box nature of commercial platforms pose challenges for developing accurate dynamics models and control policies. We address these challenges by developing a hand-crafted kinematic model for a quadruped-with-arm platform and, together with recent advances in Bayesian Neural Network (BNN)-based dynamics learning using physical priors, efficiently learn an accurate dynamics model from data. We then derive control policies for loco-manipulation via model-based reinforcement learning (RL). We demonstrate the effectiveness of this approach on hardware using the Boston Dynamics Spot with a manipulator, accurately performing dynamic end-effector trajectory tracking even in low data regimes.
2024
-
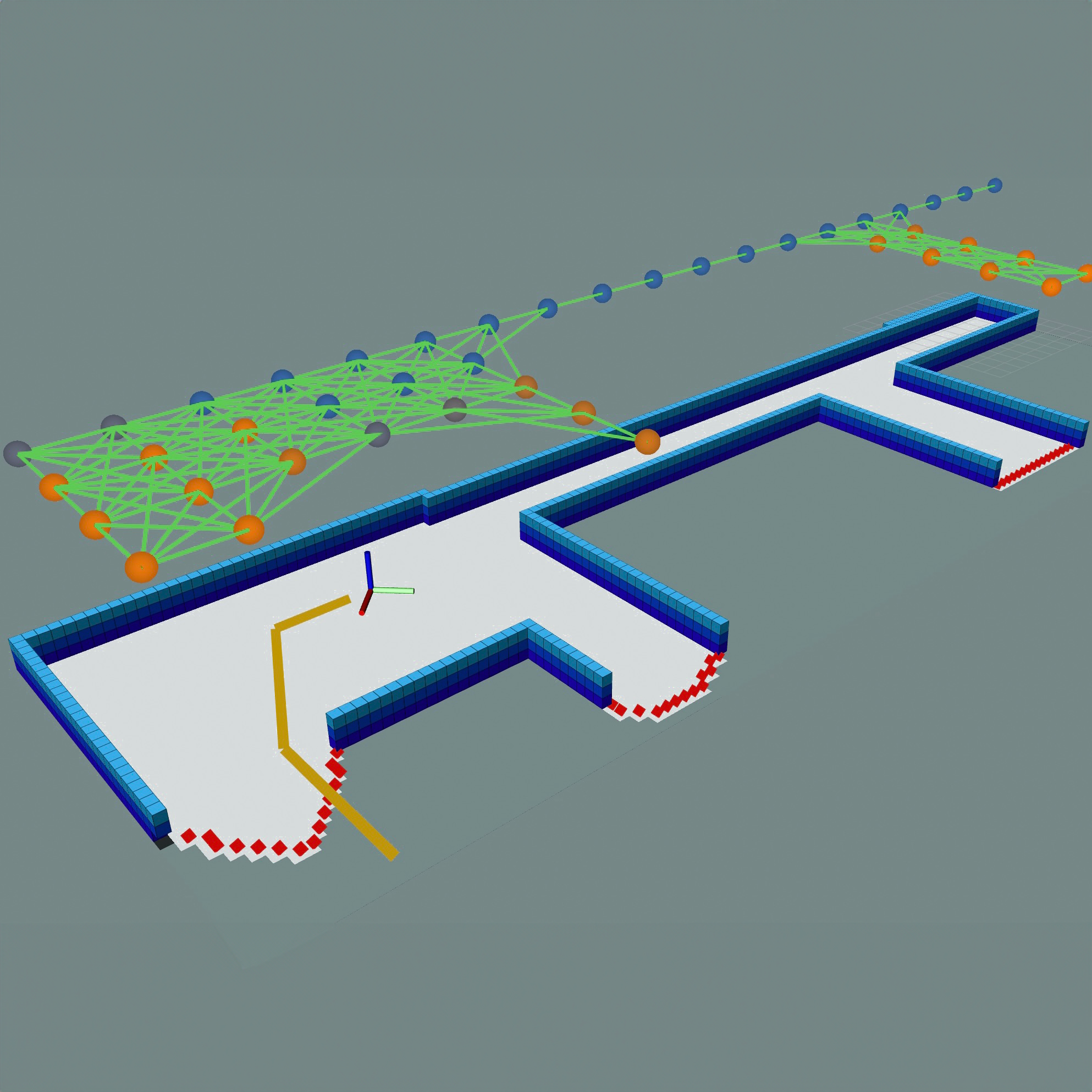 DARE: Diffusion Policy for Autonomous Robot ExplorationYuhong Cao, Jeric Lew, Jingsong Liang, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA 2025), 2024
DARE: Diffusion Policy for Autonomous Robot ExplorationYuhong Cao, Jeric Lew, Jingsong Liang, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA 2025), 2024Autonomous robot exploration requires a robot to efficiently explore and map unknown environments. Compared to conventional methods that can only optimize paths based on the current robot belief, learning-based methods show the potential to achieve improved performance by drawing on past experiences to reason about unknown areas. In this paper, we propose DARE, a novel generative approach that leverages diffusion models trained on expert demonstrations, which can explicitly generate an exploration path through one-time inference. We build DARE upon an attention-based encoder and a diffusion policy model, and introduce ground truth optimal demonstrations for training to learn better patterns for exploration. The trained planner can reason about the partial belief to recognize the potential structure in unknown areas and consider these areas during path planning. Our experiments demonstrate that DARE achieves on-par performance with both conventional and learning-based state-of-the-art exploration planners, as well as good generalizability in both simulations and real-life scenarios.
-
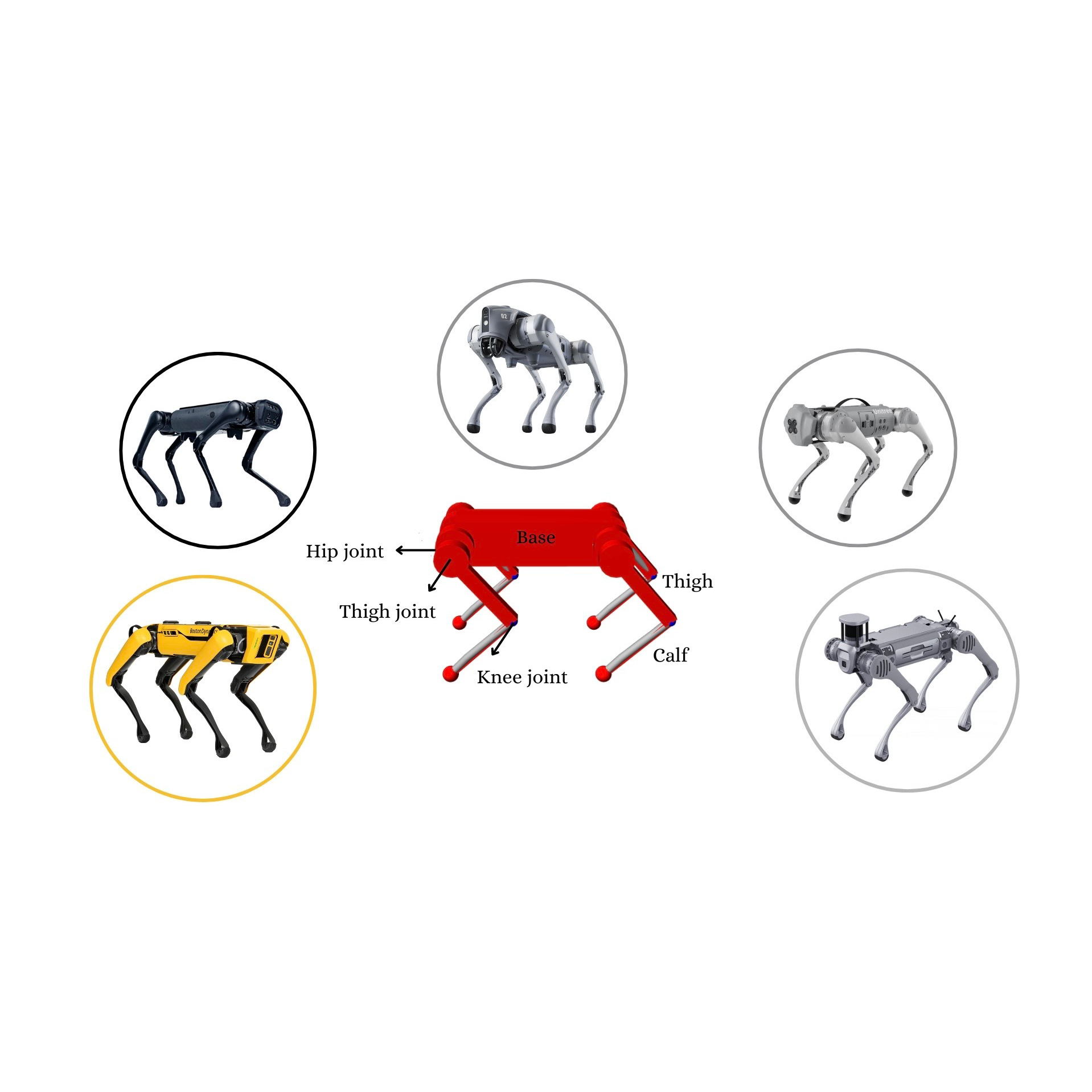 MetaLoco: Universal Quadrupedal Locomotion with Meta-Reinforcement Learning and Motion ImitationFatemeh Zargarbashi, Fabrizio Di Giuro, Jin Cheng, and 3 more authorsIn archive, 2024
MetaLoco: Universal Quadrupedal Locomotion with Meta-Reinforcement Learning and Motion ImitationFatemeh Zargarbashi, Fabrizio Di Giuro, Jin Cheng, and 3 more authorsIn archive, 2024This work presents a meta-reinforcement learning approach to develop a universal locomotion control policy capable of zero-shot generalization across diverse quadrupedal platforms. The proposed method trains an RL agent equipped with a memory unit to imitate reference motions using a small set of procedurally generated quadruped robots. Through comprehensive simulation and real-world hardware experiments, we demonstrate the efficacy of our approach in achieving locomotion across various robots without requiring robot-specific fine-tuning. Furthermore, we highlight the critical role of the memory unit in enabling generalization, facilitating rapid adaptation to changes in the robot properties, and improving sample efficiency.
-
 RobotKeyframing: Learning Locomotion with High-Level Objectives via Mixture of Dense and Sparse RewardsFatemeh Zargarbashi, Jin Cheng, Dongho Kang, and 2 more authorsConference on Robot Learning (CoRL 2024), 2024
RobotKeyframing: Learning Locomotion with High-Level Objectives via Mixture of Dense and Sparse RewardsFatemeh Zargarbashi, Jin Cheng, Dongho Kang, and 2 more authorsConference on Robot Learning (CoRL 2024), 2024This paper presents a novel learning-based control framework that uses keyframing to incorporate high-level objectives in natural locomotion for legged robots. These high-level objectives are specified as a variable number of partial or complete pose targets that are spaced arbitrarily in time. Our proposed framework utilizes a multi-critic reinforcement learning algorithm to effectively handle the mixture of dense and sparse rewards. Additionally, it employs a transformer-based encoder to accommodate a variable number of input targets, each associated with specific time-to-arrivals. Throughout simulation and hardware experiments, we demonstrate that our framework can effectively satisfy the target keyframe sequence at the required times. In the experiments, the multi-critic method significantly reduces the effort of hyperparameter tuning compared to the standard single-critic alternative. Moreover, the proposed transformer-based architecture enables robots to anticipate future goals, which results in quantitative improvements in their ability to reach their targets.
-
 Offline Diversity Maximization Under Imitation ConstraintsMarin Vlastelica, Jin Cheng, Georg Martius, and 1 more authorReinforcement Learning Conference (RLC 2024), 2024
Offline Diversity Maximization Under Imitation ConstraintsMarin Vlastelica, Jin Cheng, Georg Martius, and 1 more authorReinforcement Learning Conference (RLC 2024), 2024There has been significant recent progress in the area of unsupervised skill discovery, utilizing various information-theoretic objectives as measures of diversity. Despite these advances, challenges remain: current methods require significant online interaction, fail to leverage vast amounts of available task-agnostic data and typically lack a quantitative measure of skill utility. We address these challenges by proposing a principled offline algorithm for unsupervised skill discovery that, in addition to maximizing diversity, ensures that each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution is to connect Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Furthermore, we demonstrate the effectiveness of our method on the standard offline benchmark D4RL and on a custom offline dataset collected from a 12-DoF quadruped robot for which the policies trained in simulation transfer well to the real robotic system.
-
 Learning Diverse Skills for Local Navigation under Multi-constraint OptimalityJin Cheng, Marin Vlastelica, Pavel Kolev, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA 2024), 2024
Learning Diverse Skills for Local Navigation under Multi-constraint OptimalityJin Cheng, Marin Vlastelica, Pavel Kolev, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA 2024), 2024Despite many successful applications of data-driven control in robotics, extracting meaningful diverse behaviors remains a challenge. Typically, task performance needs to be compromised in order to achieve diversity. In many scenarios, task requirements are specified as a multitude of reward terms, each requiring a different trade-off. In this work, we take a constrained optimization viewpoint on the quality-diversity trade-off and show that we can obtain diverse policies while imposing constraints on their value functions which are defined through distinct rewards. In line with previous work, further control of the diversity level can be achieved through an attract-repel reward term motivated by the Van der Waals force. We demonstrate the effectiveness of our method on a local navigation task where a quadruped robot needs to reach the target within a finite horizon. Finally, our trained policies transfer well to the real 12-DoF quadruped robot, Solo12, and exhibit diverse agile behaviors with successful obstacle traversal.
2023
-
 RL+ Model-based Control: Using On-demand Optimal Control to Learn Versatile Legged LocomotionDongho Kang, Jin Cheng, Miguel Zamora, and 2 more authorsIEEE Robotics and Automation Letters (RA-L), 2023
RL+ Model-based Control: Using On-demand Optimal Control to Learn Versatile Legged LocomotionDongho Kang, Jin Cheng, Miguel Zamora, and 2 more authorsIEEE Robotics and Automation Letters (RA-L), 2023This letter presents a versatile control method for dynamic and robust legged locomotion that integrates model-based optimal control with reinforcement learning (RL). Our approach involves training an RL policy to imitate reference motions generated on-demand through solving a finite-horizon optimal control problem. This integration enables the policy to leverage human expertise in generating motions to imitate while also allowing it to generalize to more complex scenarios that require a more complex dynamics model. Our method successfully learns control policies capable of generating diverse quadrupedal gait patterns and maintaining stability against unexpected external perturbations in both simulation and hardware experiments. Furthermore, we demonstrate the adaptability of our method to more complex locomotion tasks on uneven terrain without the need for excessive reward shaping or hyperparameter tuning.
2022
-
 Haptic Teleoperation of High-dimensional Robotic Systems Using a Feedback MPC FrameworkJin Cheng, Firas Abi-Farraj, Farbod Farshidian, and 1 more authorIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2022), 2022
Haptic Teleoperation of High-dimensional Robotic Systems Using a Feedback MPC FrameworkJin Cheng, Firas Abi-Farraj, Farbod Farshidian, and 1 more authorIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2022), 2022Model Predictive Control (MPC) schemes have proven their efficiency in controlling high degree-of-freedom (DoF) complex robotic systems. However, they come at a high computational cost and an update rate of about tens of hertz. This relatively slow update rate hinders the possibility of stable haptic teleoperation of such systems since the slow feedback loops can cause instabilities and loss of transparency to the operator. This work presents a novel framework for transparent teleoperation of MPC-controlled complex robotic systems. In particular, we employ a feedback MPC approach [1] and exploit its structure to account for the operator input at a fast rate which is independent of the update rate of the MPC loop itself. We demonstrate our framework on a mobile manipulator platform and show that it significantly improves haptic teleoperation’s transparency and stability. We also highlight that the proposed feedback structure is constraint satisfactory and does not violate any constraints defined in the optimal control problem. To the best of our knowledge, this work is the first realization of the bilateral teleoperation of a legged manipulator using a whole-body MPC framework.